Inne podejście niż KMP
Seria zaczyna się od naiwnego wyszukiwania wzorca , gdzie widać, dlaczego podejście
Algorytm Boyer–Moore (1977) idzie inną drogą. Porównujemy wzorzec z tekstem od końca wzorca do początku. Dzięki temu pojedyncze niedopasowanie często niesie ze sobą informację, która pozwala przeskoczyć wiele znaków tekstu naraz. W typowym przypadku BM nie czyta nawet większości tekstu, osiągając sublinearną złożoność rzędu
Kluczowa idea: porównujemy od prawej
Wyrównujemy wzorzec z lewym końcem aktualnego okna w tekście, ale porównanie zaczynamy od OSTATNIEGO znaku wzorca. Jeśli ostatni znak wzorca w ogóle nie zgadza się ze znakiem w tekście, to:
- po pierwsze: odrzucamy całe to wyrównanie po jednym porównaniu,
- po drugie: często możemy od razu przesunąć wzorzec o kilka pozycji w prawo, a nie tylko o jedną.
To, o ile możemy bezpiecznie przesunąć wzorzec, wyznaczają dwie heurystyki działające niezależnie od siebie:
- reguła złego znaku (bad character),
- reguła dobrego sufiksu (good suffix).
Po niedopasowaniu liczymy obie i bierzemy z nich maksimum. Każda z nich z osobna jest poprawna (nie pominie żadnego dopasowania), więc maksimum też jest poprawne i daje większy skok.
Reguła złego znaku
Niech j będzie pozycją we wzorcu, na której nastąpiło niedopasowanie (porównujemy od prawej, więc j to indeks pierwszego niezgodnego znaku idąc od końca). Niech c = text[s + j], czyli znak w tekście, który się "nie zgodził".
Przesuwamy wzorzec tak, żeby OSTATNIE wystąpienie znaku c we wzorcu (na pozycji ściśle mniejszej niż j) trafiło dokładnie pod literę c w tekście. Jeśli c w ogóle nie występuje we wzorcu, przesuwamy wzorzec za pozycję niedopasowania, czyli o j+1 pól.
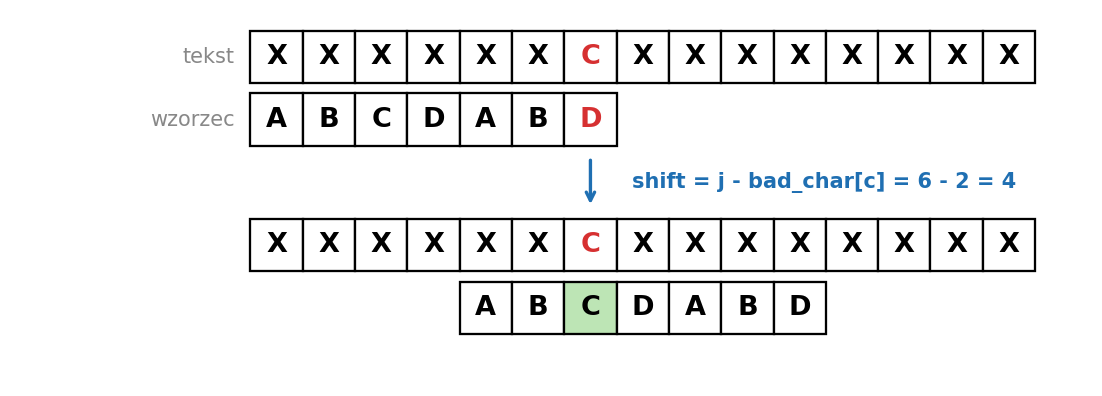
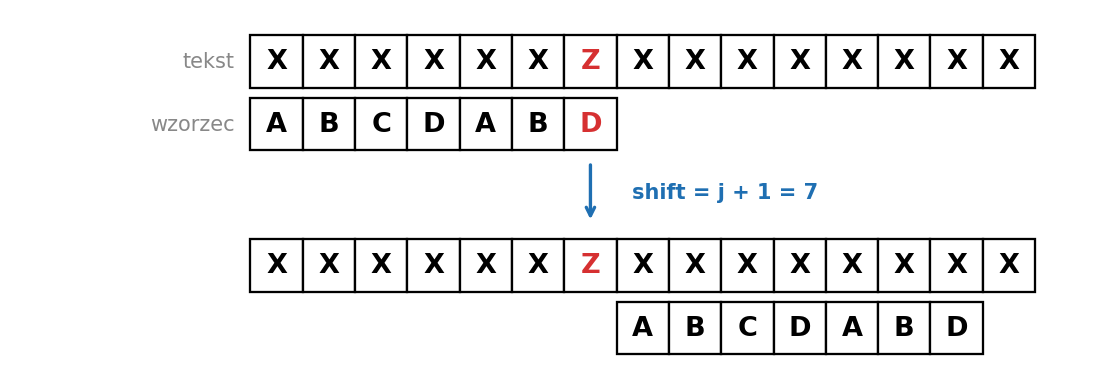
Dla każdego znaku zapisujemy indeks jego ostatniego wystąpienia we wzorcu. Dla znaków spoza wzorca przyjmujemy umownie -1. Przesunięcie liczone z reguły złego znaku to wtedy
def bad_character_table(pattern):
table = {}
for i, ch in enumerate(pattern):
table[ch] = i
return table
if __name__ == "__main__":
pattern = "ABCDABD"
table = bad_character_table(pattern)
print(f"Wzorzec: {pattern}")
print("Tablica złego znaku (ostatnie wystąpienie znaku we wzorcu):")
for ch in sorted(table):
print(f" {ch} -> {table[ch]}")
Nigdy nie cofamy okna; w najgorszym razie przesuwamy je o jedno pole. Jeśli ostatnie wystąpienie c we wzorcu znajduje się na prawo od j, wzór da liczbę ujemną. W takiej sytuacji stosujemy max(1, ...).
Reguła dobrego sufiksu
W momencie niedopasowania zazwyczaj mamy już dopasowany jakiś sufiks wzorca. Reguła dobrego sufiksu wykorzystuje tę wiedzę analogicznie do prefikso-sufiksów z KMP.
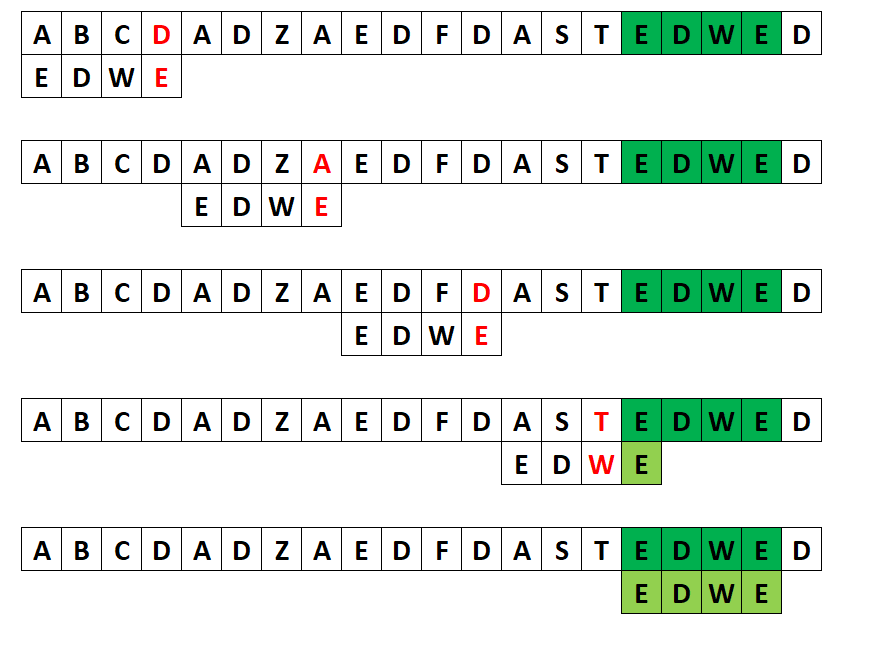
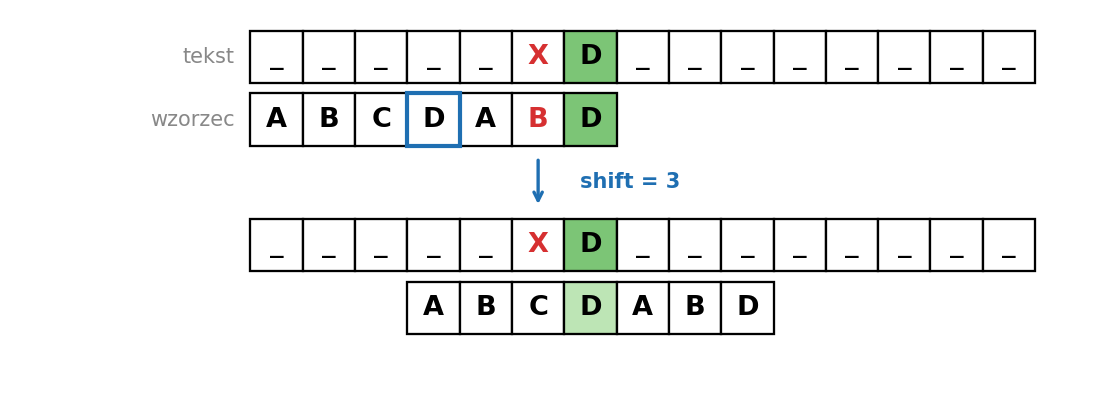
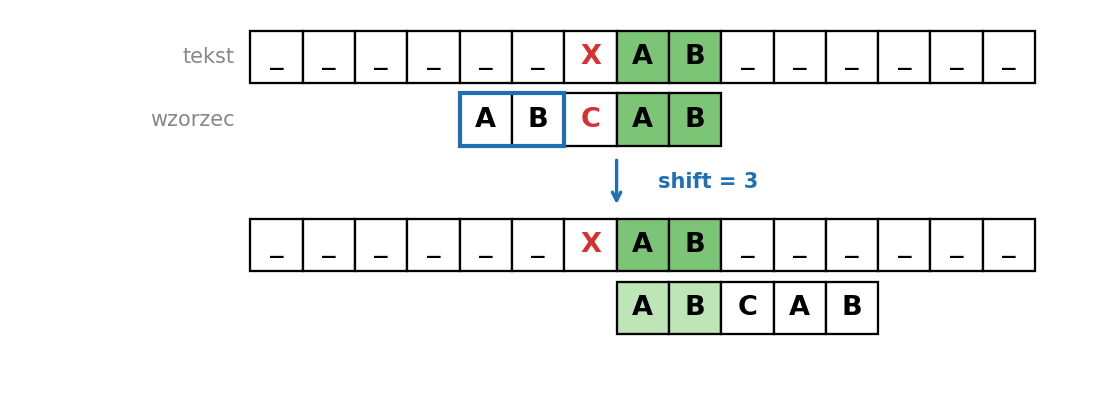
Przypadek 1: sufiks pojawia się we wzorcu
Jeśli sufiks pattern[i:] ma we wzorcu jeszcze jedno wystąpienie poprzedzone innym znakiem niż ten, który spowodował niedopasowanie, przesuwamy wzorzec tak, żeby to drugie wystąpienie sufiksu znalazło się pod jego pierwotną pozycją w tekście. Warunek „poprzedzone innym znakiem" jest analogiczny do ulepszenia Knutha w KMP (bez niego po przesunięciu od razu natrafilibyśmy na to samo niedopasowanie).
Przypadek 2: tylko prefiks wzorca pasuje do końcówki
Jeśli sufiks pattern[i:] jako całość nie występuje gdzie indziej, szukamy najdłuższego prefiksu wzorca, który jest jednocześnie sufiksem dopasowanej końcówki, i przesuwamy wzorzec tak, żeby ten prefiks trafił na koniec dopasowanego fragmentu w tekście. Jeśli i to się nie udaje, przesuwamy wzorzec o całe m pól.
Implementacja preprocessingu
def preprocess_strong_suffix(pattern):
m = len(pattern)
shift = [0] * (m + 1)
bpos = [0] * (m + 1)
bpos[m] = m + 1
j = m + 1
for i in range(m, 0, -1):
while j <= m and pattern[i - 1] != pattern[j - 1]:
shift[j] = shift[j] or (j - i)
j = bpos[j]
j -= 1
bpos[i - 1] = j
return shift, bpos
def preprocess_case2(shift, bpos):
j = bpos[0]
for i in range(len(shift)):
shift[i] = shift[i] or j
if i == j:
j = bpos[j]
return shift
def good_suffix_table(pattern):
shift, bpos = preprocess_strong_suffix(pattern)
return preprocess_case2(shift, bpos)
if __name__ == "__main__":
pattern = "ABCDABD"
shift = good_suffix_table(pattern)
print(f"Wzorzec: {pattern}")
print("Tablica dobrego sufiksu (shift[i] - przesuniecie po")
print("niedopasowaniu na pozycji i-1, sufiks pattern[i:] dopasowany):")
for i, s in enumerate(shift):
print(f" shift[{i}] = {s}")
Łączenie reguł i wyszukiwanie
Po niedopasowaniu na pozycji j mamy dwa kandydujące przesunięcia:
| Przesunięcie | Pochodzenie |
|---|---|
| reguła złego znaku | |
| reguła dobrego sufiksu |
Bierzemy z nich maksimum, na końcu zabezpieczamy się jeszcze przez max(1, ...), żeby nigdy nie zatrzymać się w miejscu:
from l1 import bad_character_table
from l2 import good_suffix_table
def boyer_moore_search(text, pattern):
n, m = len(text), len(pattern)
if m == 0 or m > n:
return 0 if m == 0 else -1
bad_char = bad_character_table(pattern)
gs_shift = good_suffix_table(pattern)
s = 0
while s <= n - m:
j = next((k for k in range(m - 1, -1, -1) if pattern[k] != text[s + k]), -1)
if j == -1:
return s
bc = j - bad_char.get(text[s + j], -1)
s += max(1, bc, gs_shift[j + 1])
return -1
if __name__ == "__main__":
text = "ABAAABCDABCDABDEABCDABDABCDABD"
pattern = "ABCDABD"
pos = boyer_moore_search(text, pattern)
print(f"Tekst: {text}")
print(f"Wzorzec: {pattern}")
print(f"Pierwsze wystapienie na pozycji: {pos}")
if pos >= 0:
print(" " * (len(f"Tekst: ") + pos) + "^" * len(pattern))
Powyższa implementacja zwraca tylko pierwsze wystąpienie wzorca w tekście. Aby znaleźć wszystkie, wystarczy po dopasowaniu nie przerywać pętli, lecz przesunąć okno o max(1, gs_shift[0]) i kontynuować.
Reguła Galila
Klasyczny BM ma jedną słabość: w pesymistycznym przypadku może osiągnąć złożoność
Reguła Galila (Zvi Galil, 1979) to drobna modyfikacja pętli wyszukiwania, która ogranicza ponowne porównania znaków już raz dopasowanych. Po przesunięciu wynikającym z reguły dobrego sufiksu (przypadek 2) lub po pełnym dopasowaniu wiemy, że pewien prefiks wzorca musi się zgadzać z fragmentem tekstu, który właśnie minęliśmy. Zamiast porównywać te znaki ponownie, zapamiętujemy granicę i pomijamy je w kolejnym porównaniu.
Dzięki temu pesymistyczny czas wyszukiwania spada z
Złożoność
| Etap | Złożoność |
|---|---|
| Preprocessing reguły złego znaku | |
| Preprocessing reguły dobrego sufiksu | |
| Wyszukiwanie — Boyer–Moore klasyczny | best |
| Wyszukiwanie — BM + reguła Galila |
| Przypadek | Kiedy się zdarza | Skutek |
|---|---|---|
| Best case | Znak z tekstu na którym pęka dopasowanie w ogóle nie występuje we wzorcu | Przesuwamy się od razu o m pozycji — dla dużego alfabetu BM bije liniowe algorytmy |
| Worst case | Patologiczny (periodyczny) wzorzec, klasyczny BM bez ulepszeń |
Kiedy używać Boyer–Moore
BM lubi:
- długie wzorce: im większe
m, tym większe potencjalne skoki, - duży alfabet: im większe
k, tym częściej znak z tekstu nie ma w ogóle odpowiednika we wzorcu, więc reguła złego znaku daje maksymalny skok.
BM przegrywa z KMP, gdy alfabet jest mały i powtarzalność tekstu duża (klasyczny przykład: dopasowywanie sekwencji DNA z 4-znakowego alfabetu). Wtedy reguła złego znaku rzadko daje duże skoki, a koszt preprocessingu i bardziej skomplikowanej pętli przeważa.
W praktyce w bibliotekach standardowych częściej spotyka się uproszczony wariant Horspoola: używa tylko reguły złego znaku w nieco prostszej wersji, ma gorszy worst-case od pełnego BM, ale jest prostszy w implementacji i zwykle wystarczająco szybki.